HTML is a Serialized Object Graph and That Changes Everything
Stop using HTML as the dumping ground for your build process du jour. We can do better.
 By Jared White
By Jared White
For the longest time I’ve struggled to articulate just how impressive and powerful HTML is and how much it grieves me to see it treated as just a “build target” of some gargantuan app development process/framework. This is how we end up with “div tag soup”:
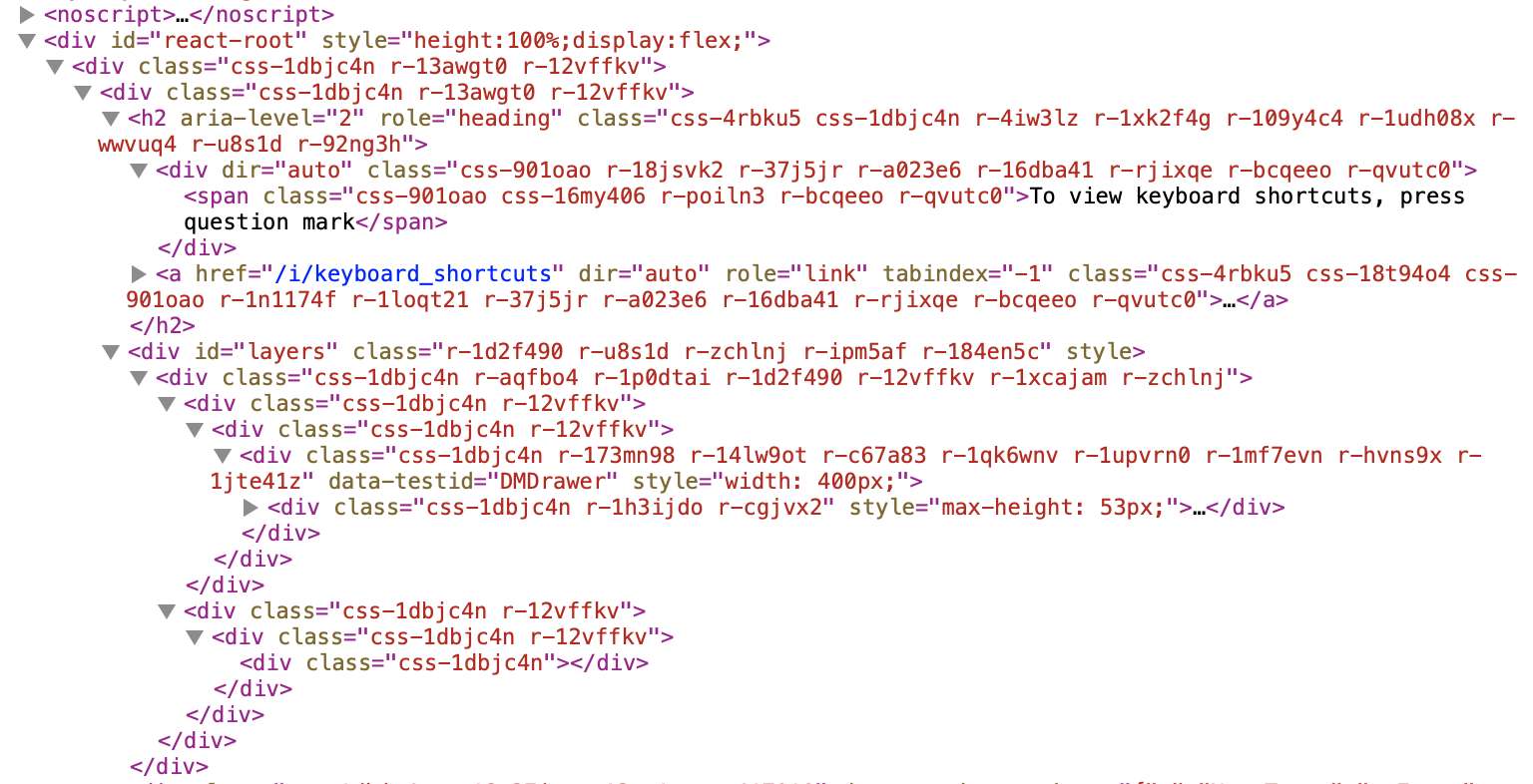
Then it finally dawned on me. The disconnect stems from the fact we don’t actually describe what HTML is properly. Hence some folks never quite grasp the full nature of the relationship HTML has with the web browser runtime.
The very short version of what happens when a browser loads a web page is this:
- It loads in the raw text of the HTML.
- It parses the HTML into series of tokens.
- Those tokens are analyzed and converted into nodes within a tree structure.
- The Document Object Model (DOM) is then constructed out of that tree and exposed to the webpage runtime (aka JavaScript).
Let’s talk about the DOM for a moment. The DOM is literally a tree of objects with special relationships to each other. All objects except the root object have a parent. Some objects have children, others do not. Many objects have siblings on one side or the other (or both).
Bear in mind we’re talking true Object-Oriented Programming (OOP) concepts here. Those objects in the DOM are available for introspection and mutation via JavaScript. Generally they are subclasses of HTMLElement. For example, a <p> tag is represented by an object of the HTMLParagraphElement class. And thanks to the Custom Element spec, we have the ability to write our own subclasses (!!) of HTMLElement. For example, a <my-fancy-tag> tag could be represented by an object of the custom class MyFancyTag.
Given all this, we swiftly come to the realization that HTML—regardless of how it’s produced—always ends up as an “object graph”: a tree of many types of objects and their relationships with one another. And knowing this truth, we discover we can actually create a living, breathing “HTML” document using imperative JavaScript statements rather than declarative markup syntax.
// Create a brand-new HTML document
const doc = document.implementation.createHTMLDocument("New Document")
// Create a new paragraph element
const p = doc.createElement("p")
p.textContent = "This is a new paragraph."
// Add the paragraph to the body of the page
doc.body.appendChild(p)
p.classList.add("text-center") // later mutation
// Let's see what it looks like as HTML!
console.log(new XMLSerializer().serializeToString(doc))
Because we’d never want to send large imperative (possibly insecure) code blocks over the network just to display a simple web page, we instead send a serialized form of that code (if you will) called—wait for it—HTML. So instead of the above, we write this:
<html>
<head>
<title>New Document</title>
</head>
<body>
<p class="text-center">This is a new paragraph.</p>
</body>
</html>
In the end, the result is exactly the same. Let me reiterate this for you because it’s vital that you get it. Once the webpage has been loaded and rendered by the browser, whether the “source code” for the page was written imperatively (via JavaScript DOM statements) or declaratively (via Hyper-Text Markup Language) is of no importance. Either way, you get a singular outcome: an object graph we call the DOM.
Why is this so important yet so tragically misunderstood? Because once you begin to grapple with the fact that HTML is in a sense a genuine programming language—technically it’s a serialized object graph which then turns into a program upon deserialization by the browser—you begin to have respect for why it’s so important to write clean, concise, and semantic HTML.
I dare you to write “div soup” imperatively in JavaScript. You’d end up with thousands of lines of document.createElement("div") and el.classList.add("hj09g872") and other incomprehensible goobledeegook. Nobody in their right mind would actually write a software program this way. It’s terrible OOP and it’s unmaintainable.
Yet people consider it acceptable, desirable even, to degrade HTML—and the DOM right along with it—by treating it as a dumping ground for some fancy-pants software development process happening elsewhere. You end up with an HTML payload—and the deserialized object graph it produces—that bears little to no resemblance to the original structure, purpose, and meaning of the content it’s supposed to represent.
My thesis is the best way to write HTML is to write it how you would write imperative code if you were to do so. For example, if I were to add a card to a webpage with a header, body, and footer, I’ll write the HTML something like this:
<my-card type="standout">
<header slot="header">
<h3>I'm a Card Header</h3>
</header>
<p>I'm in the body of the card.</p>
<footer slot="footer">
<button type="button">Action Button</button>
</footer>
</my-card>
This is exactly how I’d write the code imperatively as well. Using JavaScript I’d subclass HTMLElement as MyCard, and write any logic it needs to perform upon connection within the DOM. Then for the webpage, I’d instantiate a MyCard element and fill it with content using the appropriate semantic elements—again neatly corresponding to their object class counterparts like HTMLHeadingElement, HTMLButtonElement, etc. (Or instead of MyCard, I’d use SlCard and save myself a whole lot of trouble. 😉)
I strongly believe that in an ideal world, you should be able to read raw HTML loaded by the web browser and mentally reverse that serialized object graph into a sequence of sensibly-OOP’d code paths. Unfortunately, that’s not the case on many websites. On a whim you might choose “view source” as in days of old and immediately regret it as your eyeballs start to bleed because of how utterly dreadful the markup is.
Here’s a random example I pulled off a local transit authority’s website:
<div class="menu-item-content drawer-content js-measure" role="group" aria-hidden="true">
<ul class="wrapper">
<div class="wrapper">
<div class="l-drawer-howto l-drawer-group slice">
<div class="slice-item slice-item-double l-drawer-grouppushhigh">
<h4 class="hide">Modes</h4>
<section class="l-modesbar l-modesbar-clear">
<div class="l-modesbar-main">
<ul class="wrapper wrapper-90 slice slice-responsive">
<li class="slice-item">
Let’s see: there’s one piece of genuine semantic content lurking in there…a heading labeled Modes…which is actually hidden?! (Maybe it’s a screen reader thing?) The rest is…who knows! Maybe wacky styling requirements—sadly necessary in bygone days but now largely passé thanks to major leaps forward in CSS prowess.
And this is just one tiny piece of the overall web page!
Every single one of these tags ends up as an object in the DOM.
Every one of these tags is potential wasted memory and resources running on your computer.
Nearly every one of these tags is obscuring “the original structure, purpose, and meaning of the content it’s supposed to represent.”
This isn’t the HTML I wish to write nor consume on the web.
Why do we do it? Is it ignorance? Bad tooling? Missing knowledge of what modern CSS can do for visual layout? A lack of respect for what HTML actually is—a serialized object graph? Tight deadlines and tiny budgets?
Whatever it is, we can do better. Frameworks can do better. Tooling can do better. “Best practices” can do better. (I’m looking at you Tailwind.)
Stop using HTML as the dumping ground for your build process du jour. HTML is as deserving of careful, elegant, and maintainable OOP principles and software patterns as your actual JavaScript+ code. Do better.
P. S. Please don’t make me write a whole ‘nuther article about why the oft-cited “I only care about the source code in my repo, and what we ship to the browser can be fully obfuscated/minified because users don’t care what that looks like as long as it works/is performant/whatever” argument is completely wrong. Do your own research! 😅